 Quick tip if you use NetApp filer storage and you’d like to enable Deduplication (dedupe) and actually have it work as it was designed: Size the volumes and aggregates according to NetApp Deduplication for FAS and V-Series Deployment and Implementation Guide (TR-3505). What happens if you don’t provide enough breathing room for dedupe to run? In my experience, it runs for a second or two and completes successfully, but it does not deduplicate any data.
Quick tip if you use NetApp filer storage and you’d like to enable Deduplication (dedupe) and actually have it work as it was designed: Size the volumes and aggregates according to NetApp Deduplication for FAS and V-Series Deployment and Implementation Guide (TR-3505). What happens if you don’t provide enough breathing room for dedupe to run? In my experience, it runs for a second or two and completes successfully, but it does not deduplicate any data.
The deduplication metadata overhead space required boils down to a few variables: Data ONTAP version, volumes, and data within the volumes. All three make up the calculation. Specifically look at the tail end of section 3.3 on pages 17-18.
For Data ONTAP 7.3.x, which is what I have on the NetApp FAS 3050c filer, the following calculation applies:
1. Volume deduplication overhead – for each volume with deduplication enabled, up to 2% of the logical amount of data written to that volume will be required in order to store volume dedupe metadata. This is free space needed in the volume.
2. Aggregate deduplication overhead – for each aggregate that contains any volumes with dedupe enabled, up to 4% of the logical amount of data contained in all of those volumes with dedupe enabled will be required in order to store the aggregate dedupe metadata. This is free space needed in the aggregate.
An example used in the document:
If 100GB of data is to be deduplicated within a single volume, then there should be 2GB worth of available space within the volume and 4GB of space available within the aggregate.
Could be visualized as:

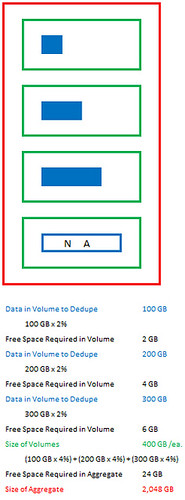
A second example with multiple volumes:
Consider a 2TB aggregate with 4 volumes each 400GB’s in size within the aggregate where three volumes are to be deduplicated, with 100GB of data, 200GB of data and 300GB of data respectively. The volumes will need 2GB, 4GB, and 6GB of space within the respective volumes; and, the aggregate will need a total of 24GB ((4% of 100GB) + (4% of 200GB) + (4%of 300GB) = 4+8+12 = 24GB) of space available within the aggregate.
Could be visualized as:
If you’ve got a filer in which to carve out some storage which needs to be deduplicated, you can go about the calculation from a few different directions.
- You can start with the aggregate whose size will be determined by spindles and protection level, then plug the remaining numbers to come up with a volume size and maximum data set size.
- Or maybe you already have the size of the data set which needs to be deduplicated. In this case, you can work the other way and determine the size of the volume required (leaving 2% available) as well as the size of the aggregate (leaving 4% available).
I take full credit for the MS Excel diagrams above. Eat your heart out Hany Michael 🙂
Update 5/13/10: Here’s another item I stumbled on… Once dedupe completes, it may not reflect any savings in the “Space saved” field highlighted below. In my case, this occurred because the iSCSI LUN carved out of the volume was not thin provisioned.
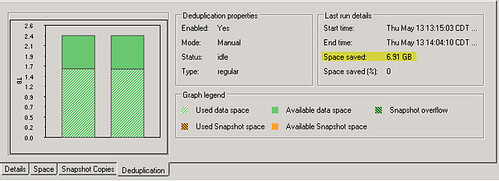
Vaughn Stewart of NetApp explained it as follows:
With NetApp, thick provisioned LUNs reserve space in the FlexVol. In other words it is a storage accounting function and not a fully written out file (like a VMDK).
If data in the LUN is deduped, the savings cannot be displayed if the thick LUN reservation is in place. Toggle the LUN to thin and savings should magically appear.
There is absolutely no change in the data layout or performance with thick or thin LUNs (thus why you can toggle the function).
This was resolved by editing the LUN properties and unchecking the “Reserved” box, and then rerunning the deduplication process on the volume.
















We gotta chip in and get you a copy of Visio!