VMware snapshotting is a wonderful and powerful technology that affords IT and Developer staff great flexibility and recovery options with virtual machines (VMs) that weren’t so flexible with physical machines or flat out did not exist. With this technology comes the responsibility of using it properly and knowing its limitations. Snapshots have a shelf life that varies somewhere between the moment the snapshot was created and infinity. Boy, that was real helpful wasn’t it?
Let me see if I can explain a little better. When a snapshot is created, a delta file is created on the VMFS volume and in the folder where the VM resides. The initial size of the delta file is 16MB. The purpose of the delta file is to maintain the delta changes to virtual disks since the snapshot was taken. This would be any disk write I/O activity inside the guest VM OS.
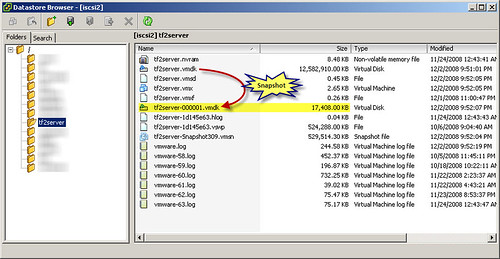
Disk write I/O inside a guest VM may be seldom or it may be very active. It depends on the role of the VM and more specifically the software and features installed inside the VM. When the initial 16MB delta file fills to capacity with the delta changes it maintains, it dynamically increases its size by another 16MB. Once again, if and when the delta file fills to capacity with delta changes, it grows by another 16MB. For those who excel in math, our delta file is now 48MB in size. Do you see the pattern? The delta file will continue to grow in 16MB increments to a maximum size of the parent file (and in some cases very rapidly!) unless one of a few conditions is met:
- Someone closes the snapshot
- Someone creates an additional child snapshot (perpetuating a potential problem)
- The snapshot file somehow becomes corrupted before or during closing of the snapshot (bad news)
- The VMFS volume where the VM and delta file are stored runs out of available storage space (update your resume. All other VMs on the same VMFS volume, snapshotted or not, as well as VMKernel swap and VM logs are now also out of write space)
Let’s connect the dots. The amount of time a snapshot should be left open is going to vary because of factors identified above. The amount of available VMFS storage, the rate at which the delta file is growing since the VM was snapped, number of VMDKs snapped, decaying VM disk performance as the delta file becomes fragmented across non-contiguous spots on disk, time to recovery if the snapshot is lost and the VM has to be restored, your personal comfort level, etc. To compound the anxiety, there are likely other VI administrators in your shop or automated backups creating and leaving snapshots open that you are unaware of on a regular basis. The urgency to have all open snapshots on your radar has increased.
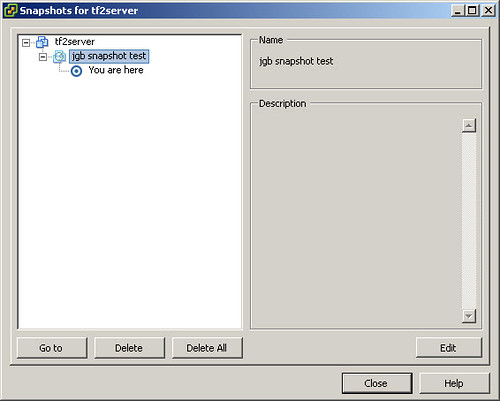
Unfortunately in the current builds, VMware doesn’t give us real good (or automated) visibility of open snapshots. I liken it to handing a loaded gun to a child – it’s only a matter of time before an accident happens. That analogy is quite extreme but it gets my point across on the importance of preventing such an accident from happening. What we have right now from the Virtual Infrastructure Client console (as well as a few of the hosted product consoles) is called the Snapshot Manager. Snapshot Manager displays open snapshots and their hierarchy – but only when we open Snapshot Manager and that’s on a VM by VM basis. Very tedious.
So how do we gain better visibility of snapshots that’s not going to tie up a bunch of our valuable time? Fortunately there are some good 3rd party solutions available for free to help us out. A few that I like are Xtravirt’s Snaphunter, RVTools, and Hyper9.
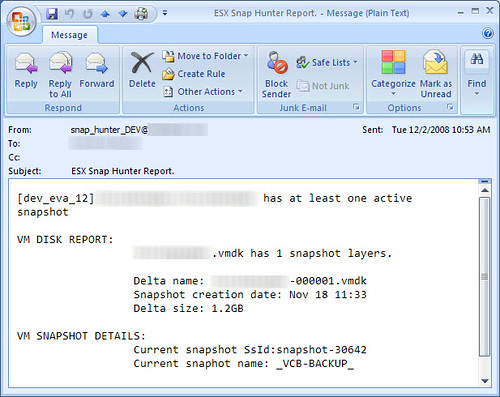
Snaphunter is a simple piece of code that you install on an ESX host and schedule scanning and emailed reports via CRON. I get two Snaphunter reports emailed to me daily at noon (1 for PROD storage, 1 for DEV storage):
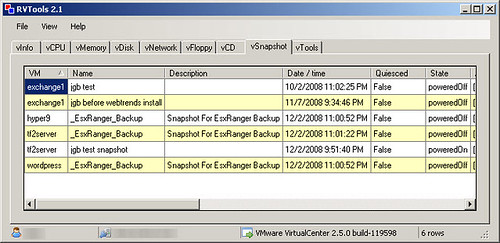
RVTools is a .NET Windows application that you can run from your desktop and get visibility of all VMs managed by a VirtualCenter instance. In addition to snapshots, RVTools shows a bunch of other cool stuff. This utility is worth checking out:
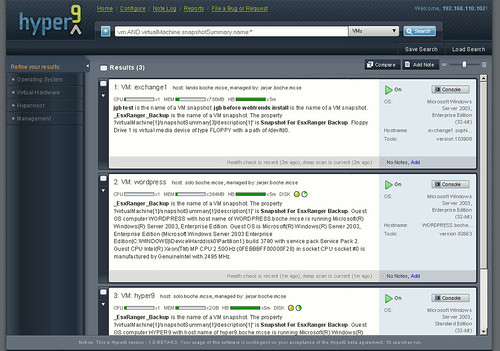
Hyper9 is an up and coming enterprise architected product (currently in beta, GA to release in early 2009) which will report on open snapshots as well as a many other facets of the virtual infrastructure:
Snapshots are so easy to create and there in and of itself lies its Achilles heel – snapshot sprawl and lack of native tools from VMware to keep them under control and keep us safe from danger.
Go forth and virtualize – but let’s be safe out there.
















Another great way to find active snapshots is the VI-toolkit.
Jason,
I’m a little confused about a statement you make in this post. With regards to the situation where the VMFS volume fills up b/c of one or more growing snapshots – my understanding was that only VMs on the same volume that are operating with snapshots would be impacted. VMs not running snapshots are not impacted b/c they are contained within their swap and VMDK files.
I personally use HP SIM to watch my logical volume free space and I run daily schedule snaphunter jobs. Still, I want to better understand the risks.
Thanks much for the clarification.
Tristan
VMs need room to breathe for their *.log files, VMKernel swap (if they are swapping), power operations for VMs that previously were not powered on, snapshotting (we run backups which snapshot nightly). I’ve never actually run a VMFS volume down to 0KB free. I’m not 100% confident on the short term impacts, nor do I know if VMFS is even going to let us get down to 0KB free. At any rate, even coming close to 0KB free on a VMFS volume does not sound like an attractive position to be in from a VM performance and available standpoint. I’ve got 1 DEV LUN that sits at about 23GB free and that is awfully close to my comfort threshold. The moment any one of the VMs on that LUN gets snapped, space starts disappearing. Hopefully the snap is closed before we run out of space, or before we cross whatever threshold VMware has when performance tanks or anomalies start happening. It would be a good experiment for the lab.
Jason,
I totally agree. I’m going to create this situation in my lab to learn more about the impact and timing. Thanks for the quick response – your community contributions are much appreciated!
Tristan
Jason,
Thanks for the write up, by happen stance, do you know if any of the third party tools will happen to support ESXi, Foundation / Enterprise in the future?
We are currently contemplating ESX vs ESXi for our Data Center.
Thanks.
Roger L
Roger,
Not sure on the 3rd party tools, but with the VI-Toolkit for Windows finding snapshots is really easy.
Go here to get started:
http://vmware.com/go/powershell/
Then to list all snapshots:
connect-viserver -name (your esx or VC)
get-vm | get-snapshot
To list snapshots older than 7 days:
connect-viserver -name (your esx or VC)
get-vm | get-snapshotwhere | where { $_.Created -le (Get-Date).AddDays(-7)}
-Cody
Jason,
VMFS will let you get ‘close’ to 0KB. When you do, “Bad Things Happen” – e.g. Chuck Norris divides by zero, and the like. Troubleshooting it is an interesting thing, and usually involves some small amount of pain deleting snapshots from the CLI.
-Cody
http://professionalvmware.com
We have had a VMFS volume fill in our environment due to a backup that did not close out the snapshot when it was finished. Needless to say we were excited when all the bells and warnings were going off saying that a server had gone offline.
What we found was that the only systems that were affected were those writing to the disk. Fortunately our environment was well designed and very balanced so the only machines that were directly affected were those with snapshots running (and in this instance just the one server).
One side effect to note is that the only way to recover from this is to make some space so that you can apply the snapshots. This is where storage vmotion might come in handy allowing you to move a VM to a different LUN. We chose the cold move approach since I was not confident that sVmotion wouldn’t require some disk writing. When this happened to us we had over 50GB worth of snapshots to be applied (main production file share running Volume Shadow Copy for those wondering how it got so big). Took about 2.5 hours to recover from this event but at least it was at the end of the day. This is one thing to be wary about with having a large “comfort cushion” on your VMFS datastore.
Needless to say I check my VMs (manually now for the highest disk I/O servers) to ensure that backups did not leave us a little friend waiting like a scorpion in a shoe.
I plan to write a full entry in the coming week(s) to my slowly developing blog.