Here’s a discussion that has somewhat come full circle for me and could prove to be a handy for those with lab or production environments alike.
A little over a week ago I was having lunch with a former colleague and naturally a TPS discussion broke out. We talked about how it worked and how effective it was with small memory pages (4KB in size) as well as large memory pages (2MB in size). The topic was brought up with a purpose in mind.
Many moons ago, VMware virtualized datacenters consisted mainly of Windows 2000 Server and Windows Server 2003 virtual machines which natively leverage small memory pages – an attribute built into the guest operating system itself. Later, Windows Vista as well as 2008 and its successors came onto the scene allocating large memory pages by default (again – at the guest OS layer) to boost performance for certain workload types. To maintain flexibility and feature support, VMware ESX and ESXi hosts have supported large pages by default providing the guest operating system requested them. For those operating systems that still used the smaller memory pages, those were supported by the hypervisor as well. This support and configuration remains the default today in vSphere 5.1 in an advanced host-wide setting called Mem.AllocGuestLargePage (1 to enable and support both large and small pages – the default, 0 to disable and force small pages). VMware released a small whitepaper covering this subject several years ago titled Large Page Performance which summarizes lab test results and provides the steps required to toggle large pages in the hypervisor as well as within Windows Server 2003
As legacy Windows platforms were slowly but surely replaced by their Windows Server 2008, R2, and now 2012 predecessors, something began to happen. Consolidation ratios gated by memory (very typical mainstream constraint in most environments I’ve managed and shared stories about) started to slip. Part of this can be attributed to the larger memory footprints assigned to the newer operating systems. That makes sense, but this only explains a portion of the story. The balance of memory has evaporated as a result of modern guest operating systems using large 2MB memory pages which will not be consolidated by the TPS mechanism (until a severe memory pressure threshold is crossed but that’s another story discussed here and here).
For some environments, many I imagine, this is becoming a problem which manifests itself as an infrastructure capacity growth requirement as guest operating systems are upgraded. Those with chargeback models where the customer or business unit paid up front at the door for their VM or vApp shells are now getting pinched because compute infrastructure doesn’t spread as thin as it once did. This will be most pronounced in the largest of environments. A pod or block architecture that once supplied infrastructure for 500 or 1,000 VMs now fills up with significantly less.
So when I said this discussion has come full circle, I meant it. A few years ago Duncan Epping wrote an article called KB Article 1020524 (TPS and Nehalem) and a portion of this blog post more or less took place in the comments section. Buried in there was a comment I had made while being involved in the discussion (although I don’t remember it). So I was a bit surprised when a Google search dug that up. It wasn’t the first time that has happened and I’m sure it won’t be the last.
Back to reality. After my lunch time discussion with Jim, I decided to head to my lab which, from a guest OS perspective, was all Windows Server 2008 R2 or better, plus a bit of Linux for the appliances. Knowing that the majority of my guests were consuming large memory pages, how much more TPS savings would result if I forced small memory pages on the host? So I evacuated a vSphere host using maintenance mode, configured Mem.AllocGuestLargePage to a value of 0, then placed all the VMs back onto the host. Shown below are the before and after results.
A decrease in physical memory utilization of nearly 20% per host – TPS is alive again:
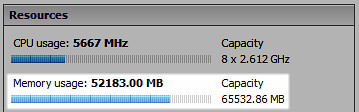
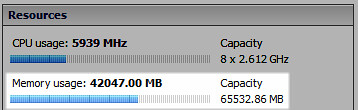
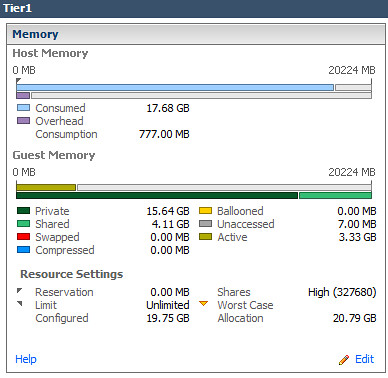
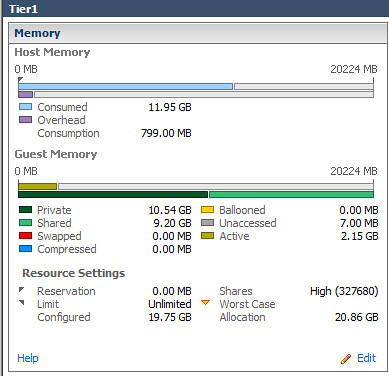
124% increase in Shared memory in Tier1 virtual Machines:
90% increase in Shared memory in Tier3 virtual Machines:
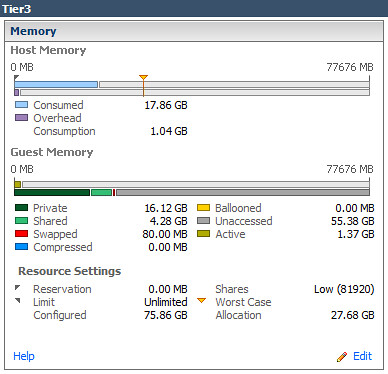
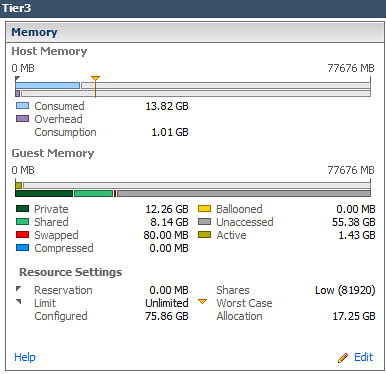
Perhaps what was most interesting was the manner in which TPS consolidated pages once small pages were enabled. The impact was not realized right away nor was it a gradual gain in memory efficiency as vSphere scanned for duplicate pages. Rather it seemed to happen in batch almost all at once 12 hours after large pages had been disabled and VMs had been moved back onto the host:
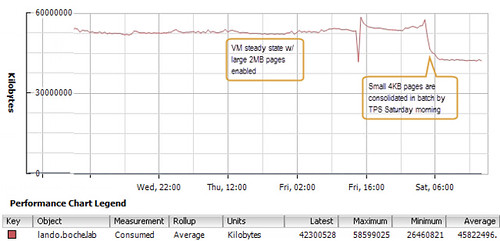
So for those of you who may be scratching your heads wondering what is happening to your consolidation ratios lately, perhaps this has some or everything to do with it. Is there an action item to be carried out here? That depends on what your top priority when comparing infrastructure performance in one hand and maximized consolidation in the other.
Those who are on a lean infrastructure budget (home lab would be an ideal fit here), consider forcing small pages to greatly enhance TPS opportunities to stretch your lab dollar which has been getting consumed by modern operating systems and and increasing number of VMware and 3rd party appliances.
Can you safely disable large pages in production clusters? It’s a performance question I can’t answer that globally. You may or may not see performance hit to your virtual machines based on their workloads. Remember that the use of small memory pages and AMD Rapid Virtualization Indexing (RVI) and Intel Extended Page Tables (EPT) is mutually exclusive. Due diligence testing is required for each environment. As it is a per host setting, testing with the use of vMotion really couldn’t be easier. Simply disable large pages on one host in a cluster and migrate the virtual machines in question to that host and let them simmer. Compare performance metrics before and after. Query your users for performance feedback (phrase the question in a way that implies you added horsepower instead of asking the opposite “did the application seem slower?”)
That said, I’d be curious to hear if anyone in the community disables large pages in their environments as a regular habit or documented build procedure and what the impact has been if any on both the memory utilization as well as performance.
Last but not least, Duncan has another good blog post titled How many pages can be shared if Large Pages are broken up? Take a look at that for some tips on using ESXTOP to monitor TPS activity.
Update 3/21/13: I didn’t realize Gabrie had written about this topic back in January 2011. Be sure to check out his post Large Pages, Transparent Page Sharing and how they influence the consolidation ratio. Sorry Gabrie, hopeuflly understand I wasn’t trying to steal your hard work and originality 🙂
Update 10/20/14: VMware announced last week that inter-VM TPS (memory page sharing between VMs, not to be confused with memory page sharing within a single VM) will no longer be enabled by default. This default ESXi configuration change will take place in December 2014.
VMware KB Article 2080735 explains Inter-Virtual Machine TPS will no longer be enabled by default starting with the following releases:
ESXi 5.5 Update release – Q1 2015
ESXi 5.1 Update release – Q4 2014
ESXi 5.0 Update release – Q1 2015
The next major version of ESXiAdministrators may revert to the previous behavior if they so wish.
and…
Prior to the above ESXi Update releases, VMware will release ESXi patches that introduce additional TPS management capabilities. These ESXi patches will not change the existing settings for inter-VM TPS. The planned ESXi patch releases are:
ESXi 5.5 Patch 3. For more information, see VMware ESXi 5.5, Patch ESXi550-201410401-BG: Updates esx-base (2087359).
ESXi 5.1 patch planned for Q4, 2014
ESXi 5.0 patch planned for Q4, 2014
The divergence is in response to new research which leveraged TPS to gain unauthorized access to data. Under certain circumstances, a data security breach may occur which effectively makes TPS across VMs a vulnerability.
Although VMware believes the risk of TPS being used to gather sensitive information is low, we strive to ensure that products ship with default settings that are as secure as possible.
Additional information, including the introduction of the Mem.ShareForceSalting host config option, is available in VMware KB Article 2091682 Additional Transparent Page Sharing management capabilities in ESXi 5.5 patch October 16, 2014 and ESXi 5.1 and 5.0 patches in Q4, 2014
As well as the VMware blog article Transparent Page Sharing – additional management capabilities and new default settings
















Great Post Jason!
I am in fact wondering about what happens to the performance of the VMs when changing the Mem.AllocGuestLargePage setting (that you alluded to wondering as well in your post)
But even if it does affect performance of the virtual machines, this is very interesting for lab environments that can’t support as many resources on the hypervisor.
Thanks for digging into this.
Great post!
Same topic raised during VMware PEX.
I had this customer who was under memory contention and thought it was a good time to add more memory to its hosts.
Right after he complained that memory usage cranked up by a large amount that it used to be before the memory upgrade.
The things is that TPS used to kick in and reduced memory usage by 50% or more, giving the customer a false/positive feeling that the his VMs were not memory bond.
Now that the virtual platforms have much more memory resources at its disposal, there is no more memory contention and thus TPS doesn’t kick in anymore… The immediate impact is that memory usage is way high compared to former situation.
Regarding performance, customer did not notice any improvement or degradation.
Rgds,
Didier
Jason,
Thanks for your insight into this. This is a great write up.
Interesting note.
I have changed this on production hosts while running, it does not require a reboot, and I believe the documentation says it checks for shared pages every hour.
I have found I have to run this on my VDI hosts. Obviously, VDI benefits greatly from sharing, as most users use the OS and office applications (I see 40% sharing or so)
Once again, great post Jason,
Like everyone else, I’m a bit curious to see what the performance implications are on the VMs when forcing small memory pages. It’s a pretty important variable to the discussion. Another element I think has also changed in production environments – CPU requirements. Memory had typically been the resource that most of us had run out of first; making TPS really important. Changing RAM densities have changed this somewhat, but more importantly, Newer Operating Systems need more CPU. All too often a single vCPU just doesn’t cut it the way it used to – whether it be for Linux or Windows. Whether it is serving up Exchange, or a CRM, or Win7 VDI VMs, frugal vCPU settings just don’t cut it like they did for Win2003/XP generation of systems. (A bit of a corner case, but I’m running nearly 30 code compiling VMs with 8vCPUs a piece) Needing more CPU ends up balancing out what resource ultimately ends up being the constraint on the host.
Keep up the great work!
– Pete
I disable large pages by default on our production and test systems (non-VDI too) because of the huge memory savings we’re able to achieve by this.
Personally, without having performed any kind of representative benchmarking, I can say that I haven’t seen it affecting performance. I assume it might be measurable in very synthetic memory benchmarks, which have little significance for real-world workloads though.
I’d also love to see some solid numbers comparing both cases instead of nebulous claims/assumptions I’ve seen somewhere regarding this.
Anyways I think it’s also important to note that Mem.AllocGuestLargePage is a completely Guest-OS agnostic setting and purely about how the vmkernel manages the hosts physical memory.
Whether the Guest OS uses large pages to manage its own virtual memory resources or not is in no way related to this setting. (This is also why a vMotion, which the guest is unaware of, triggers the effect.)
A Guest and ESXi host can benefit independently from using large pages from their own perspective (if that is notable is another question), but I do not think there are any additional synergy effects by using large pages on both ends.
This is a topic that I’ve spent more time researching and thinking about than I’d like to admit.
What’s interesting to me is that it doesn’t seem like switching to small pages manually is actually increasing your consolidation ratios; it’s only giving you a better picture of what you *really* have. In other words, if you leave large pages turned on and continue to throw more virtual machines onto the host, you’ll find that large pages get broken into small pages, TPS works some more of its magic, and you’ll probably see a little bit ballooning. Essentially, you get to the same end result without turning off large pages. However, the main difference is that there’s no way to tell when you’re going to hit “the tipping point” where noticeable performance degradation begins to take place. There’s no way to know if you should be buying more hardware yesterday. it’s just guesswork.
The big problem that my customers are seeing is lack of visibility into their *true* consolidation potential. I had one customer do an experiment on a six-host cluster that *appeared* to be at around 90% of its memory capacity. One by one he started putting hosts into maintenance mode. After the first host, VMs were moved onto the remaining five, some large pages broke down into small ones, TPS kicked in a bit more, and a little ballooning took place. Cluster memory capacity was at around 90% again. No noticeable performance issues for VMs. He repeated this again with a second host – same results. He didn’t go any further because the potential risk was higher. How much further could he have gone? No one knows. The lack of valuable visibility is what is killing consolidation ratios, in my opinion.
How to solve this problem? I’ve been doing some research and pondering on this for a couple of years and I’ve come up with a few potential ideas. I’m curious to get input from the rest of the community since the problem has gone on for years without a solution from VMware:
1. Validate which workloads actually require the performance of large memory pages.
Maybe we’ll find that 90% of the time the difference is negligible, leading most of us to just turn off large pages. Maybe we can just put VMs that need large pages on a separate cluster.
2. Find or create a better memory usage metric.
Right now, hosts and clusters use Memory Consumed, which is skewed by large memory pages, caching, etc. Memory Active is out of the question for most of us who are familiar with it because it largely understates the memory resources that are required by VMs. I’ve tried using combinations of metrics (e.g. consumed – zero pages) and haven’t found anything that is reliable yet.
3. Create an automated memory consolidation test.
Create a VM with large pages enabled, memory hot-add, and as few resource shares as possible. In an automated fashion, continue to increase the memory allocation on the test VM steadily until it begins to see performance degradation – excessive ballooning, swapping in the OS, etc. Because the test VM has super low shares, it will experience all the adverse performance effects first, while still forcing small pages and TPS to take effect. In the end, the size of the test VM will be the amount of additional memory you have available.
Hi Jonathan, good to hear from you. If you’ve stayed put, we’re on the same team now 🙂
Your analysis of consolidation perception is spot on and this has been suggested by at least one other person that I know of. Technically customers could continue to add workloads to hosts thereby increasing memory pressure to the point that various memory overcommit mechanisms start becoming effective, including TPS. But the reality is that most customers probably aren’t going to do this – they are guided by the perception that their hosts are at running capacity from a memory perspective and most would or should be stopping well short of the mid-90% required for page breakdown (capacity headroom is needed on each host for N+1, N+2 HA designs). The last shop I worked at as a customer, our policy was host full at 80% at memory or CPU (in almost all cases it was memory). The difference being now with large pages is that they are at capacity before memory overcommit versus previously being at capacity after memory overcommit with small pages.
Based on my experience as a customer, I’d guestimate that VMware sees a larger volume of support cases from customers pushing the limits of overcommitted resources. Strange things go bump in the night with hosts running in the high 90% of resource utilization. The host tips over or HOSTD fails or becomes unstable stranding running VMs on it which then requires an outage.
In the last 3 years we’ve seen our hosts go from 72GB of ram to 384GB (18x4GB to 24x16GB), for roughly the same cost. This more than makes up for any reduction in TPS or increase in typical ram allocation. If you’re stuck with old hardware and an evolving workload I can see the need, but if you have any ability to spend some capital dollars you’ll see a huge bang for the buck in purchasing new hosts, and thanks to the death of the vRam tax the hardware is almost the only cost.
One VMware customer is looking at a $3M capex spend to make up for lost capacity. I don’t know what the breakdown is between hardware, licensing, and maintenance.
I worked in a 1000 VM environment on Wall Street until last year. When I upgraded to our hosts to newer boxes that supported MMU our consolidation ratio really took a hit. I was shocked that, what VMware touted for so long was gone… All memory sharing! After some digging I learned of the TPS situation.
We had setup a charge back system for all of our business units based on a certain memory sharing amount. And for many years our applications / VMs lived for years on small pages and performed perfectly file. As I’m sure many companies are, they’re VMs are pretty CPU sleepy for the most part.
In this environment our hosts were over allocated by nearly 40% and never experienced swapping. When the upgrade happened we hit the ceiling and ran into performance problems due to the slowness of TPS kicking when memory pressure was felt. VMs ending up with some pages swapped out and performance took a hit.
I think VMware now wants you NOT to overcommit your memory and use large pages. It’s a tough pill to swallow to watch an ESXi host running at 90%+ and not expect performance problems when someone boots up one more VM.
Plus, it’s hard to detect when you are *actually* out of host memory without running everything in small pages before. The manageability of an environment that must overcommit was really difficult. I ended up running some bench mark tests with and without the advanced setting set to “0.” There was about a 5% decrease in performance when small pages were enabled. It was our choice to force small pages in favor of a much improved consolidation ratio. Even with 320 GB of ram and 12 physical cores we were still memory bound with nearly 40% overcommitment. Even with that consolidation ratio our CPU ready was still within spec and not causing issues. In my opinion, VMware loses a lot of credit when they have nearly zero memory sharing out of the box. Everyone says… “Ahh… don’t worry about it… TPS will do its thing when the time comes.” I didn’t buy it as there was no way to tell how far you could push the ESXi host and what the actual memory amount used would be in times of contention when small pages were invoked. Our solution… Invoke them all the time and take the 5% CPU performance hit. This allow us to better estimate the growth of the environment and keep a perfectly acceptable level of performance without buying many more hosts.
Just tried this in my lab environment and went from 20+ GB of memory used to 4GB. Nice!