Here’s a discussion that has somewhat come full circle for me and could prove to be a handy for those with lab or production environments alike.
A little over a week ago I was having lunch with a former colleague and naturally a TPS discussion broke out. We talked about how it worked and how effective it was with small memory pages (4KB in size) as well as large memory pages (2MB in size). The topic was brought up with a purpose in mind.
Many moons ago, VMware virtualized datacenters consisted mainly of Windows 2000 Server and Windows Server 2003 virtual machines which natively leverage small memory pages – an attribute built into the guest operating system itself. Later, Windows Vista as well as 2008 and its successors came onto the scene allocating large memory pages by default (again – at the guest OS layer) to boost performance for certain workload types. To maintain flexibility and feature support, VMware ESX and ESXi hosts have supported large pages by default providing the guest operating system requested them. For those operating systems that still used the smaller memory pages, those were supported by the hypervisor as well. This support and configuration remains the default today in vSphere 5.1 in an advanced host-wide setting called Mem.AllocGuestLargePage (1 to enable and support both large and small pages – the default, 0 to disable and force small pages). VMware released a small whitepaper covering this subject several years ago titled Large Page Performance which summarizes lab test results and provides the steps required to toggle large pages in the hypervisor as well as within Windows Server 2003
As legacy Windows platforms were slowly but surely replaced by their Windows Server 2008, R2, and now 2012 predecessors, something began to happen. Consolidation ratios gated by memory (very typical mainstream constraint in most environments I’ve managed and shared stories about) started to slip. Part of this can be attributed to the larger memory footprints assigned to the newer operating systems. That makes sense, but this only explains a portion of the story. The balance of memory has evaporated as a result of modern guest operating systems using large 2MB memory pages which will not be consolidated by the TPS mechanism (until a severe memory pressure threshold is crossed but that’s another story discussed here and here).
For some environments, many I imagine, this is becoming a problem which manifests itself as an infrastructure capacity growth requirement as guest operating systems are upgraded. Those with chargeback models where the customer or business unit paid up front at the door for their VM or vApp shells are now getting pinched because compute infrastructure doesn’t spread as thin as it once did. This will be most pronounced in the largest of environments. A pod or block architecture that once supplied infrastructure for 500 or 1,000 VMs now fills up with significantly less.
So when I said this discussion has come full circle, I meant it. A few years ago Duncan Epping wrote an article called KB Article 1020524 (TPS and Nehalem) and a portion of this blog post more or less took place in the comments section. Buried in there was a comment I had made while being involved in the discussion (although I don’t remember it). So I was a bit surprised when a Google search dug that up. It wasn’t the first time that has happened and I’m sure it won’t be the last.
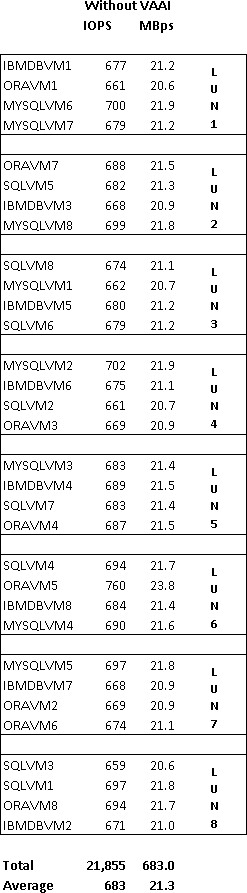
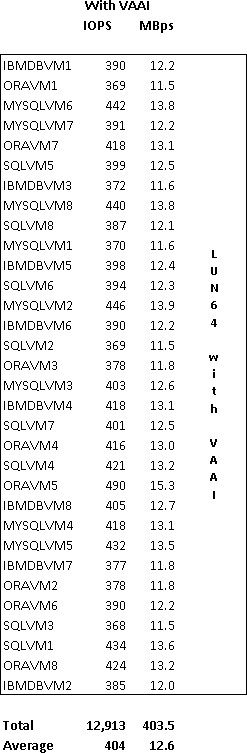
Back to reality. After my lunch time discussion with Jim, I decided to head to my lab which, from a guest OS perspective, was all Windows Server 2008 R2 or better, plus a bit of Linux for the appliances. Knowing that the majority of my guests were consuming large memory pages, how much more TPS savings would result if I forced small memory pages on the host? So I evacuated a vSphere host using maintenance mode, configured Mem.AllocGuestLargePage to a value of 0, then placed all the VMs back onto the host. Shown below are the before and after results.
A decrease in physical memory utilization of nearly 20% per host – TPS is alive again:
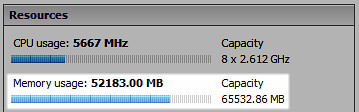
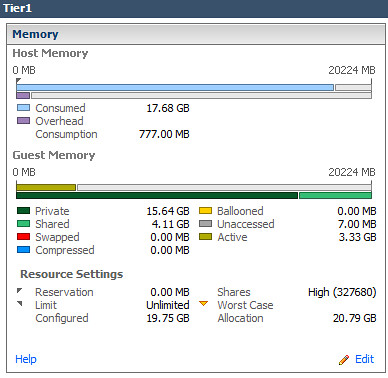
124% increase in Shared memory in Tier1 virtual Machines:
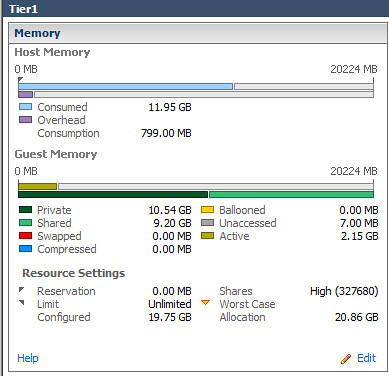
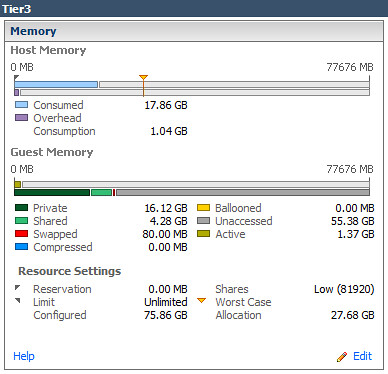
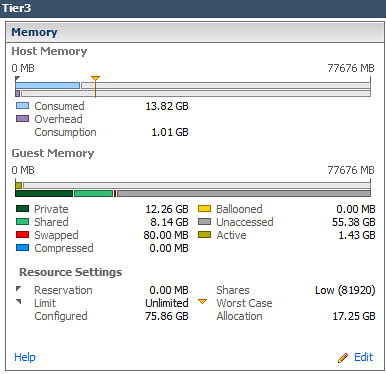
90% increase in Shared memory in Tier3 virtual Machines:
Perhaps what was most interesting was the manner in which TPS consolidated pages once small pages were enabled. The impact was not realized right away nor was it a gradual gain in memory efficiency as vSphere scanned for duplicate pages. Rather it seemed to happen in batch almost all at once 12 hours after large pages had been disabled and VMs had been moved back onto the host:
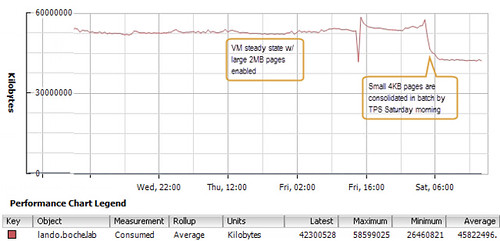
So for those of you who may be scratching your heads wondering what is happening to your consolidation ratios lately, perhaps this has some or everything to do with it. Is there an action item to be carried out here? That depends on what your top priority when comparing infrastructure performance in one hand and maximized consolidation in the other.
Those who are on a lean infrastructure budget (home lab would be an ideal fit here), consider forcing small pages to greatly enhance TPS opportunities to stretch your lab dollar which has been getting consumed by modern operating systems and and increasing number of VMware and 3rd party appliances.
Can you safely disable large pages in production clusters? It’s a performance question I can’t answer that globally. You may or may not see performance hit to your virtual machines based on their workloads. Remember that the use of small memory pages and AMD Rapid Virtualization Indexing (RVI) and Intel Extended Page Tables (EPT) is mutually exclusive. Due diligence testing is required for each environment. As it is a per host setting, testing with the use of vMotion really couldn’t be easier. Simply disable large pages on one host in a cluster and migrate the virtual machines in question to that host and let them simmer. Compare performance metrics before and after. Query your users for performance feedback (phrase the question in a way that implies you added horsepower instead of asking the opposite “did the application seem slower?”)
That said, I’d be curious to hear if anyone in the community disables large pages in their environments as a regular habit or documented build procedure and what the impact has been if any on both the memory utilization as well as performance.
Last but not least, Duncan has another good blog post titled How many pages can be shared if Large Pages are broken up? Take a look at that for some tips on using ESXTOP to monitor TPS activity.
Update 3/21/13: I didn’t realize Gabrie had written about this topic back in January 2011. Be sure to check out his post Large Pages, Transparent Page Sharing and how they influence the consolidation ratio. Sorry Gabrie, hopeuflly understand I wasn’t trying to steal your hard work and originality 🙂
Update 10/20/14: VMware announced last week that inter-VM TPS (memory page sharing between VMs, not to be confused with memory page sharing within a single VM) will no longer be enabled by default. This default ESXi configuration change will take place in December 2014.
VMware KB Article 2080735 explains Inter-Virtual Machine TPS will no longer be enabled by default starting with the following releases:
ESXi 5.5 Update release – Q1 2015
ESXi 5.1 Update release – Q4 2014
ESXi 5.0 Update release – Q1 2015
The next major version of ESXiAdministrators may revert to the previous behavior if they so wish.
and…
Prior to the above ESXi Update releases, VMware will release ESXi patches that introduce additional TPS management capabilities. These ESXi patches will not change the existing settings for inter-VM TPS. The planned ESXi patch releases are:
ESXi 5.5 Patch 3. For more information, see VMware ESXi 5.5, Patch ESXi550-201410401-BG: Updates esx-base (2087359).
ESXi 5.1 patch planned for Q4, 2014
ESXi 5.0 patch planned for Q4, 2014
The divergence is in response to new research which leveraged TPS to gain unauthorized access to data. Under certain circumstances, a data security breach may occur which effectively makes TPS across VMs a vulnerability.
Although VMware believes the risk of TPS being used to gather sensitive information is low, we strive to ensure that products ship with default settings that are as secure as possible.
Additional information, including the introduction of the Mem.ShareForceSalting host config option, is available in VMware KB Article 2091682 Additional Transparent Page Sharing management capabilities in ESXi 5.5 patch October 16, 2014 and ESXi 5.1 and 5.0 patches in Q4, 2014
As well as the VMware blog article Transparent Page Sharing – additional management capabilities and new default settings